Global and Local Critical Policy Learning for Abstractive Summarization
This was a class project for the course Information Retrieval II:
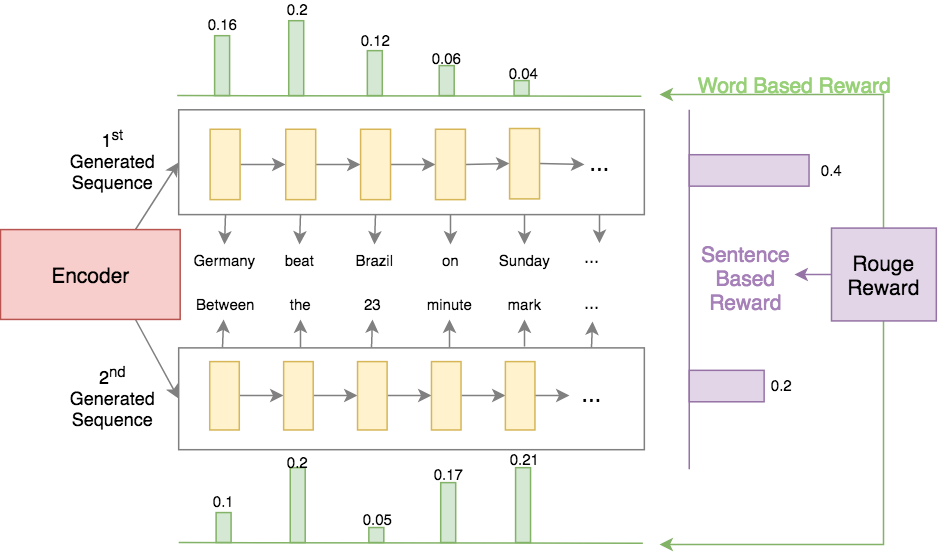
Traditional Abstractive Summarization models suffer from training directly using a maximum likelihood approach, which is known to decrease the models’ abstractive power and therefore generate summaries which are less human-like in abstraction. Our approach attempts to solve this by incorporating a local (word level) and global (sentence level) loss weighting using the ROUGE metric directly as a reward in a Policy Gradient. By evaluating the sub-sequences of the generated summary, we can obtain the gain they provide in ROUGE score for the entire summary and weigh the loss locally and globally to reflect this.
Our new loss and training procedure pushes the networks closer to the golden reference summaries and allows us to optimize for ROUGE score and increase the abstractiveness of the generated summaries. Reweighing loss by the local and global rewards give the generator a better understanding of what parts of the generated summary are better than others. We are able to considerably surpass a baseline generator trained using MLE, by using a mix of our local and global approaches with more emphasis on local rewards. We expect that using the proposed training extension can help boost the ROUGE scores of any summary generators.
You can view the full PDF report here and the Github repo can be found here